Accessibility Concept Emergence in the Pythia Suite: Thresholds, Binding, and the Declarative-Evaluative Gap
This started as a question about whether LLMs understand accessibility well enough to be useful tools. It turned into something about how meaning gets built — and lost — inside the network.
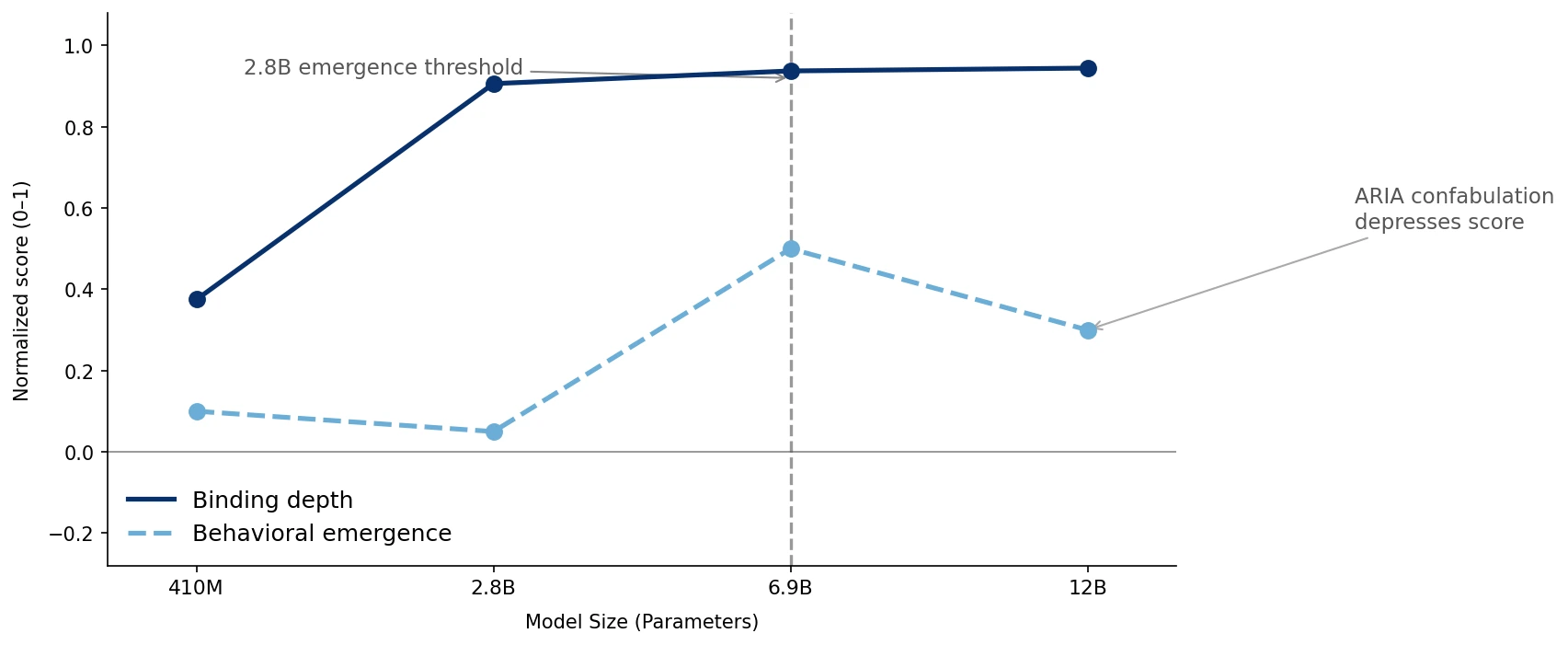
Sustained deep-network binding of accessibility compounds appears to be a necessary structural condition for behavioral capability — present in every model that correctly defines core concepts, absent in every model that fails.
We use the Web Content Accessibility Guidelines (WCAG) as our test domain because accessibility represents a specialized, low-frequency vocabulary in web-scale training data: a small, well-defined set of terms with unambiguous answers and direct relevance to real-world tooling decisions. That makes it an unusually clean lens for studying emergence — concepts concrete enough to evaluate, rare enough to show scale sensitivity.
Using the Pythia suite (160M–12B) and GPT-2 (small–XL) with TransformerLens, we investigate not just what models know but how that knowledge is encoded internally. All models show compound binding in early layers; the differentiating factor is whether that binding persists into late network layers. Screen reader, skip link, and alt text emerge behaviorally at ~2.8B parameters; WCAG first appears at 6.9B; ARIA (Accessible Rich Internet Applications) exhibits fluent wrongness at every scale tested — producing confident, plausible expansions that are consistently incorrect.
Models prefer correct definitions before they can produce them, and a declarative-evaluative gap persists even at maximum scale: models that correctly define accessibility concepts cannot reliably identify violations in code. The gap is robust across 15 prompts spanning three elicitation strategies, and isn’t an artifact of prompt design. Entropy analysis reveals that the gap has internal structure — the model enters distinct failure states depending on how it’s asked, from high-entropy stalling to low-entropy confident parroting.
Extending the binding analysis to Pythia 12B introduces a late-layer resurgence pattern: a cluster of binding heads re-engaging near the output layers that scales monotonically with model size.
Read the full preprint on Authorea · DOI: 10.22541/au.177282002.24340653/v2